
Introduction
In
addition to writing PL/SQL code and constructing SQL queries, database
developers are often called on to design table structures. Wouldn’t it
be great if there was a weekly quiz to test and improve your knowledge
of data modelling to help you with this? Well now there can be!
To
complement the existing PL/SQL and SQL quizzes, we (Steven Feuerstein and Chris Saxon, a longtime PL/SQL Challenge player who is offering to administer this quiz) propose the creation of a new weekly "Database Design" quiz as part of the PL/SQL
Challenge. The intended scope of this quiz is:
- Reading and understanding database schema diagrams
- Determining how to apply database constraints (e.g. foreign keys, unique constraints, etc. ) to enforce business rules
- Understanding and application of database theory (normal forms, star schemas, etc.)
- Appropriate indexing strategies and physical design considerations (e.g. partitioning, index organised tables, etc.)
Below
is a starting set of assumptions and three example quizzes. Please have
a read of these and send us your thoughts on whether or not you would
be interested in a database design quiz and the nature of the questions.
Thanks!
Steven and Chris
Thanks!
Steven and Chris
Assumptions
All schema diagrams shown will be drawn using Oracle Data Modeler, using the following settings:
* The Logical Model Notation Type of Barker
* Relational Model Foreign Key Arrow Direction set to “From Foreign Key to Primary Key”
To indicate constraints on columns, the following will appear next to them:
- An asterisk indicates that the column is mandatory (i.e. not null)
- P means this forms part of the primary key for the table
- F means this forms part of a foreign key to another table
- U means this forms part of a unique constraint on the table
For normal forms, the following definitions are used:
First Normal Form (1NF):
- Table must be two-dimensional, with rows and columns.
- Each row contains data that pertains to one thing or one portion of a thing.
- Each column contains data for a single attribute of the thing being described.
- Each cell (intersection of row and column) of the table must be single-valued.
- All entries in a column must be of the same kind.
- Each column must have a unique name.
- No two rows may be identical.
- The order of the columns and of the rows does not matter.
- There is (at least) one column or set of columns that uniquely identify a row
- Date’s definition that all columns must be mandatory for a table to be in 1NF will not be included for the purposes of this quiz.
Second Normal Form (2NF):
- Table must be in first normal form (1NF).
- All nonkey attributes (columns) must be dependent on the entire key.
Third Normal Form (3NF):
- Table must be in second normal form (2NF).
- Table has no transitive dependencies.
Boyce-Codd Normal Form (BCNF)
- Table must be in third normal form
- Table has no overlapping keys (that is two or more candidate keys that have one or more columns in common)
*
The only database objects that exist are those shown in the quiz or are
available in a default installation of Oracle Enterprise Edition
*
There is no relationship between different answers within a quiz. The
correctness of one choice has no impact on the correctness of any other
choice.
* All code (PL/SQL blocks, DDL statements, SQL statements, etc.) is run in Oracle's SQL*Plus.
* The
edition of the database instance is Enterprise Edition; the database
character set is ASCII-based with single-byte encoding; and a dedicated
server connection is used. The version of the Oracle client software
stack matches that of the database instance.
* All
code in the question and in the multiple choice options run in the same
session (and concurrent sessions do not play a role in the quiz unless
specified). The schema in which the code runs has sufficient system and
object privileges to perform the specified activities.
* When
analyzing or testing choices, you should assume that for each choice,
you are starting "fresh" - no code has been run previously except that
required to install the Oracle Database and then any code in the
question text itself.
* The
session and the environment in which the quiz code executes has enabled
output from DBMS_OUTPUT with an unlimited buffer size, using the
equivalent of the SQL*Plus SET SERVEROUTPUT ON SIZE UNLIMITED FORMAT
WRAPPED command to do the enabling. The SET DEFINE OFF command has been
executed so that embedded "&" characters will not result in prompts
for input. Unless otherwise specified, assume that the schema in which
the code executes is not SYS nor SYSTEM, nor does it have SYSDBA
privileges.
*
Index performance will be measured in terms of the “constistent gets”
metric, as reported when enabling autotrace. This will be done using the
command: “set autotrace trace” in SQL*Plus.
Q1: Topic: Understanding entity relationship diagrams
Difficulty: Beginner
Below is a schema diagram showing a table structure for storing order and product details in a database: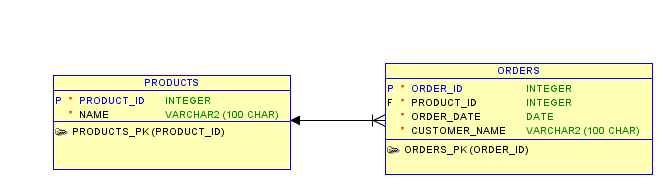
Given this structure, which of the following statements are true:
Questions
Q1. All orders must be linked to a product.
Q2. An order may be linked to more than one product.
Q3. A product may be associated with multiple orders.
Q4. It is not possible to have products with no linked orders.
Answers
A1.
Correct. The ORDERS.PRODUCT_ID column is a mandatory foreign key to the
PRODUCTS table, as denoted by the F (foreign key) and asterisk
(mandatory) next to this column.
A2. Wrong. Only one value can be stored in the ORDERS.PRODUCT_ID column for a given ORDERS row.
A3.
Correct. There is no unique constraint on the ORDERS.PRODUCT_ID column,
therefore the same product can be listed on more than one row in the
ORDERS table.
A4.
Wrong. As the ORDERS.PRODUCT_ID column is mandatory, an entry must
exist in the PRODUCTS table before an order can be linked to it.
Therefore it must be possible to have a product with no associated
orders.
Q3 Topic: 3rd normal form
Difficulty: Intermediate
A
new social networking site is under development and work is taking
place on the user profile page. The current requirements are a profile
page should be able to display:
* A user’s email address
* Their name
* Their date of birth
* Their astrological star sign (determined from the day and month of their birth)
You’ve been asked to design the table to store this information and have come up with the following:
create table plch_user_profile (
user_id integer primary key,
email varchar2(320) not null unique,
display_name varchar2(200),
date_of_birth date not null,
star_sign varchar2(10)
);
Unfortunately,
the data architect isn’t happy with this, saying the table isn’t in
third normal form! How can this be changed so it complies with third
normal form while still meeting the requirements above?
Questions
Q1. Remove the unique constraint on the EMAIL column.
Q2. Remove the STAR_SIGN column from the table.
Q3. Change the DATE_OF_BIRTH column to accept null values.
Q4. Remove the DATE_OF_BIRTH column from the table.
Answers
A1.
Wrong. Removing this constraint means we still have a dependency
between DATE_OF_BIRTH and STAR_SIGN, which can lead to "update
anomalies" if only one of these columns is changed. To meet third normal
form, we must remove one of these columns.
A2.
Correct. We can calculate a person's star sign from the day and month
of their birth, so we can still display a person's star sign on their
profile if we just store their date of birth.
A3.
Wrong. There’s still a (non-prime) dependency between DATE_OF_BIRTH and
STAR_SIGN. This means it is possible to enter a (date_of_birth,
star_sign) pair that isn't valid in the real world (e.g. 1st Jan 1980,
Libra)
A4.
Wrong. Removing DATE_OF_BIRTH from the table does remove the non-prime
dependency DATE_OF_BIRTH->STAR_SIGN so the table is now in third
normal form. However, we can't determine the DATE_OF_BIRTH just from a
peron's star sign, meaning we no longer meet the business requirement to
display this!
Q3 Topic: Indexing strategies
Difficulty: Intermediate
We have the following table that stores details of customer orders:
create table plch_orders (
order_id integer primary key,
customer_id integer not null,
order_date date not null,
order_status varchar2(20) check (
order_status in ('UNPAID', 'NOT SHIPPED', 'COMPLETE', 'RETURNED', 'REFUNDED')),
notes varchar2(50)
);
This
stores over a million orders that have been placed over the past ten
years. The vast majority (>95%) of the orders have the status of
COMPLETE. There are a few thousand different customers that place
approximately one order per month.
Recently
there’s been complaints from customers that their orders are taking a
long time to arrive, so your boss wants a daily report displaying the
PLCH_ORDERS.CUSTOMER_ID for orders that have been placed within the past
month that have not yet been shipped. You put together the following
query:
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';
Unfortunately,
there's currently no indexes on the columns used in this query so it's
taking a long time to run! Which of the following indexes can we create
that can benefit the performane of this query:
Questions
Q1. create index plch_unshipped on plch_orders (order_status);
Q2. create index plch_unshipped on plch_orders (order_status, order_date);
Q3. create index plch_unshipped on plch_orders (order_status, order_date, customer_id);
Q4. create index plch_unshipped on plch_orders (customer_id);
Q5. create index plch_unshipped on plch_orders ( customer_id, order_date, order_status);
Q6. create index plch_unshipped on plch_orders ( customer_id, order_status);
Answers
A1. Correct. Only a small percentage of orders will have the status "NOT SHIPPED" so an index on this will be beneficial.
A2.
Correct. Adding the date to the index enables Oracle to filter the data
even further, requiring fewer rows to be inspected in the table.
A3. Correct. This is a "fully covering" index, meaning the query can be answered without having to access the table at all.
A4.
Wrong. CUSTOMER_ID doesn’t appear in the where clause of the query,
therefore it is not available to Oracle to improve the execution of this
query.
A5.
Correct. This also a "fully covering" index, so the Oracle can answer
the query by just inspecting the index without accessing the table.
However, this will result in an “INDEX FAST FULL SCAN” rather than an
“INDEX RANGE SCAN” as in answer three which is less efficient. This is
because CUSTOMER_ID is the first column in the index, so Oracle is not
able to access the NOT SHIPPED rows directly. Instead it must scan
through the whole index
A6.
Wrong. For an index to be considered by the optimizer then the first
column(s) in the index must be in the where clause. If the leading
columns have a low distinct cardinality, then Oracle can choose to
perform an "index skip scan" operation. However, we have a large number
of different customers in this case, so a skip scan is not possible.
Verification Code
create table plch_orders (
order_id integer primary key,
customer_id integer not null,
order_date date not null,
order_status varchar2(20) check (
order_status in ('UNPAID', 'NOT SHIPPED', 'COMPLETE', 'RETURNED', 'REFUNDED')),
notes varchar2(50));
insert into plch_orders
select rownum, mod(rownum, 3179),
sysdate - ((1000000-rownum)/1000000)*3650,
case when rownum <= 950000 then 'COMPLETE'
else decode(mod(rownum, 5),
0, 'COMPLETE',
1, 'UNPAID',
2, 'NOT SHIPPED',
3, 'RETURNED',
4, 'REFUNDED')
end,
dbms_random.string('x', 50)
from dual
connect by level <= 1000000;
commit;
exec dbms_stats.gather_table_stats(user, 'plch_orders', cascade => true);
set autotrace trace
PRO default query results in full table scan
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';
create index plch_unshipped on plch_orders (order_status);
exec dbms_stats.gather_table_stats(user, 'plch_orders', cascade => true);
PRO Index range scan with table access by rowid
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';
drop index plch_unshipped;
create index plch_unshipped on plch_orders (order_status, order_date);
exec dbms_stats.gather_table_stats(user, 'plch_orders', cascade => true);
PRO Index range scan with table accesss by rowid.
PRO Because order_date is included, this is index is more selective so results in fewer consistent gets
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';
drop index plch_unshipped;
create index plch_unshipped on plch_orders (order_status, order_date, customer_id);
exec dbms_stats.gather_table_stats(user, 'plch_orders', cascade => true);
PRO Index range scan with no table access. The most efficient option
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';
drop index plch_unshipped;
create index plch_unshipped on plch_orders (customer_id);
exec dbms_stats.gather_table_stats(user, 'plch_orders', cascade => true);
PRO Causes a full table scan as in the un-indexed example
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';
drop index plch_unshipped;
create index plch_unshipped on plch_orders (customer_id, order_date, order_status);
exec dbms_stats.gather_table_stats(user, 'plch_orders', cascade => true);
PRO Results in an index fast full scan. This is less efficient than the other correct examples,
PRO but is still more efficient than a FTS, resulting in ~1/3 fewer consistent gets in my example
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';
drop index plch_unshipped;
create index plch_unshipped on plch_orders (customer_id, order_status);
exec dbms_stats.gather_table_stats(user, 'plch_orders', cascade => true);
PRO Results in a full table scan as in the unindexed example
select customer_id
from plch_orders
where order_date > add_months(sysdate, -1)
and order_status = 'NOT SHIPPED';